
🕷 Scrapear Web con Python y depositar contenido en Google Sheets (Nivel Chuck Norris)

👋👋👋 ¡Hola a todos! 👋👋👋
Hace tiempo que tenia ganas de publicar un articulo como este, pero por una cosa o la otra siempre lo fui postergando, por fin llego el momento de salir a la luz.
Al final de este articulo vas a poder Scrapear una Web con Python y depositar todos los resultados en un SpreadSheets de Google, te voy a explicar el código de punta a punta y dejare el código fuente para que no tengas que hacer nada de nada. ¿Qué tul?
¡Aclaración importante!
No voy a explicar Python, básicamente por que no es un curso de python 🙂, con lo cual si no sabes ni de que se trata, te recomiendo que leas algunos tutoriales y luego vuelvas.
Aclarado esto, ¡Arranquemos! 💪
De esto voy hablar
¿Cuál es la idea?
Básicamente quiero scrapear contenido de sitios web y depositar los resultados obtenidos en un Google Sheets, ni mas ni menos que eso.
Ya entrando en la parte técnica, el proyecto lo podemos separar en tres partes 👇
- Un Archivo TXT que tendrá el listado de todas las url que vamos a scrapear
- El código Python
- El volcado de datos al Google Sheets
Ahora te voy a mostrar como funciona esta joyita 💎, lo primero es tener en claro que queremos scrapear, y obviamente como es algo masivo necesitamos el listado de links victimas de nuestra arañita..
1️⃣ Listado de Links
Para este ejemplo voy a tomar la tan famosa web de Romuald Fons Avesexoticas.org, lo siento romu 🙏 🤣
El listado de links lo voy a tomar ni mas ni menos que del post-sitemap.xml de la pagina.
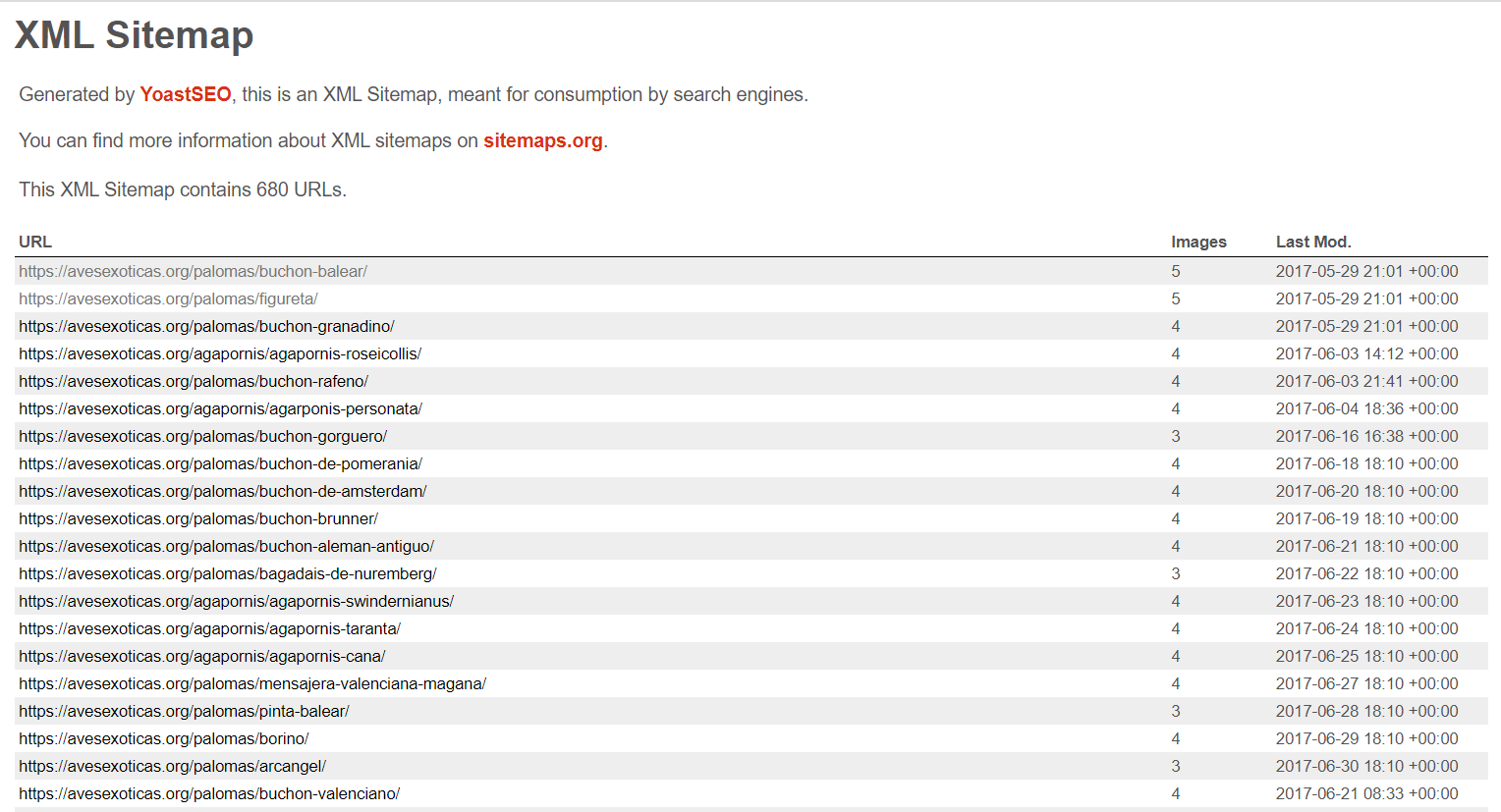
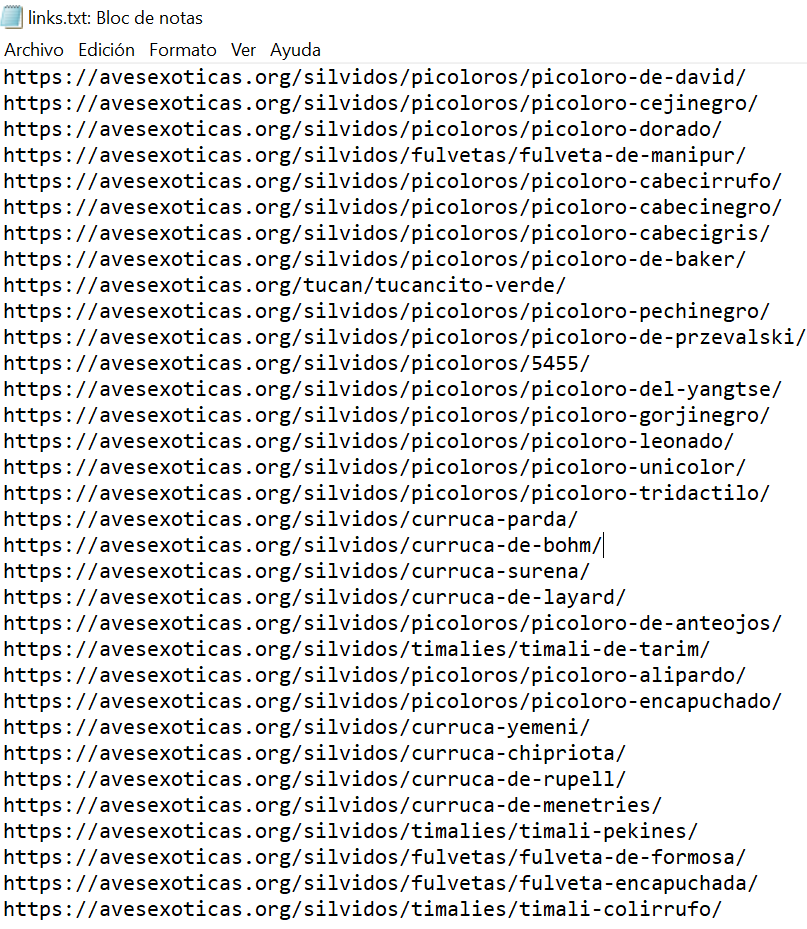
Copio todas las URL y las pego en un txt, en este caso son mas de 600, se ve que los redactores de romu tuvieron mucho trabajo. 🤣 👇
2️⃣ Script Python
Ahora que ya tenemos los links en el txt, tenemos que ir a nuestro archivo python y vincularlo, para eso lo hacemos colocando la ruta donde esta el archivo en la siguiente linea, así como esta con dos barras invertidas.
path = 'c:\\python_proyects\\scrapper\\links.txt'
Yo lo dejo en la misma carpeta todo, el archivo txt y el script python.
from bs4 import BeautifulSoup
import requests
import os
path = 'c:\\python_proyects\\scrapper\\links.txt'
with open(path, 'r') as fichero:
for link in fichero.readlines():
page = requests.get(link.rstrip('\n'))
if page.status_code == 200:
soup = BeautifulSoup(page.content, "lxml")
try:
box = soup.find("main",class_='site-main')
h1 = box.find('h1').get_text()
parrafo = box.find('p').get_text()
img = box.find('div',class_='post-thumbnail').find('img').get('src')
## Guardo todo en Google Sheets
USER_AGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:65.0) Gecko/20100101 Firefox/65.0"
URL_LOG = f"https://docs.google.com/forms/d/e/1FAIpQLSd_381rz3qMuh5esMu3nN4USC1x8RqoIJHaaQQQxFfSXdFedA/formResponse?entry.1028304341={h1}&entry.524117291={parrafo}&entry.155032278={img}"
resp = requests.get(URL_LOG,USER_AGENT)
print(resp.status_code)
except:
print("Error")
Ahora si, te voy a pedir atención por que esta es la parte clave de todo, yo tome la decisión de scrapear el h1, el párrafo del h1 y la imagen destacada.
Y como te imaginaras, eso se lo tenemos que informar al Script, claro magia no hace 🤷♂️
Presta atención, esa configuración la hago acá 👇
box = soup.find("main",class_='site-main')
h1 = box.find('h1').get_text()
parrafo = box.find('p').get_text()
img = box.find('div',class_='post-thumbnail').find('img').get('src')Te explico brevemente, en esta linea identifico el contenedor HTML donde se encuentran todo el contenido del articulo, eso se ve muy fácil haciendo F12 en la pagina (doy por sentado que sabes hacerlo).
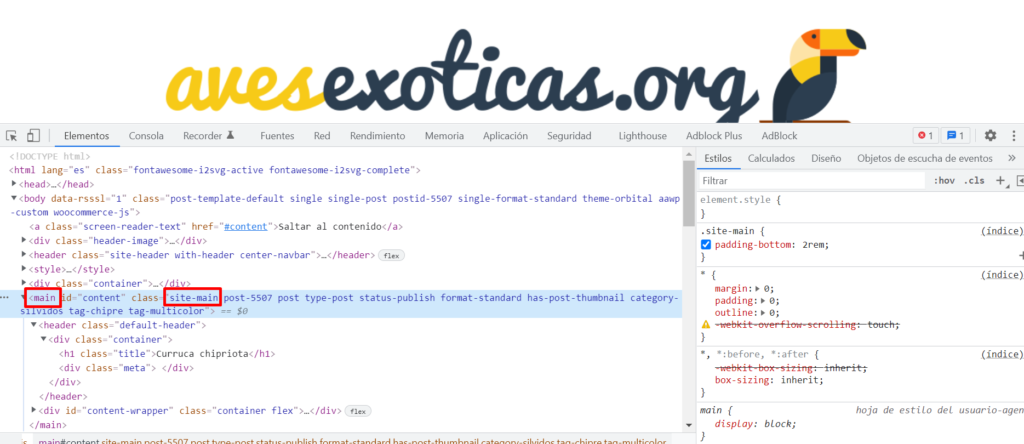
Como veras, el primer argumento de la función find es la etiqueta, en este caso main, y en el segundo personalizo con la clase "site-main", quizás en esta ocasión no era necesario dado que hay una sola etiqueta main en todo el articulo, pero mejor prevenir que curar.
Ahora si, en las siguientes dos líneas le pido a python que me devuelva el texto h1 y el primer párrafo que aparezca dentro del contenedor que definimos antes.
h1 = box.find('h1').get_text()
parrafo = box.find('p').get_text()Y para la imagen, hago lo mismo que al comienzo, me fijo en el codigo fuente del articulo cual es la clase que quiero tomar.
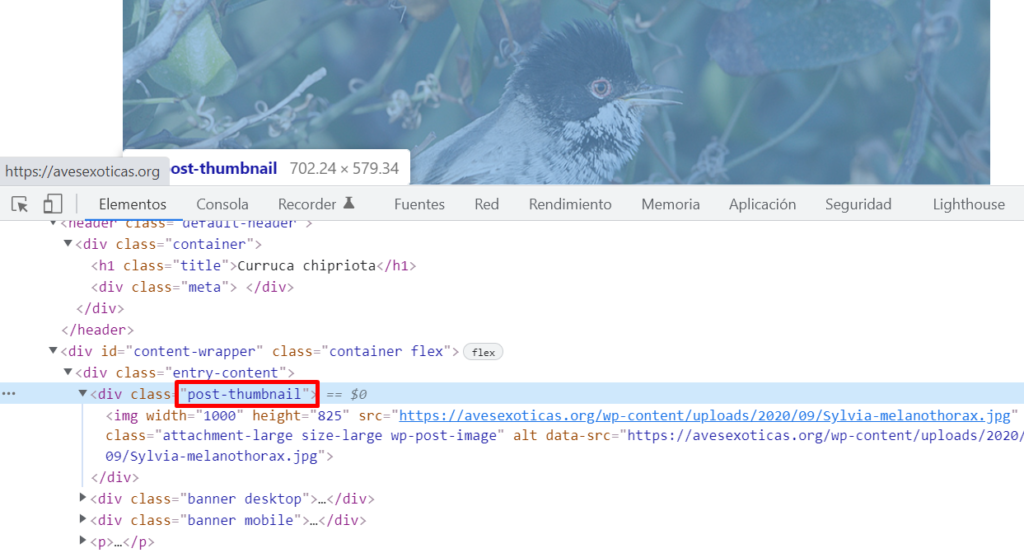
img = box.find('div',class_='post-thumbnail').find('img').get('src')¡Y listo esta parte!
Lo se, si te cuesta la parte técnica del SEO puede que tengas dificultades para poder implementarlo sin problemas, me ofrezco ayudarte en lo que pueda solo tienes que contactarme a través de los comentarios o por Twitter y te respondo 🙂.
3️⃣ Guardando los datos en Google Sheets
Esto si que va a ser difícil de explicar je, pero vamos a intentar ser lo mas claro posible. 👇
Primero Paso (Vamos a Google Forms)
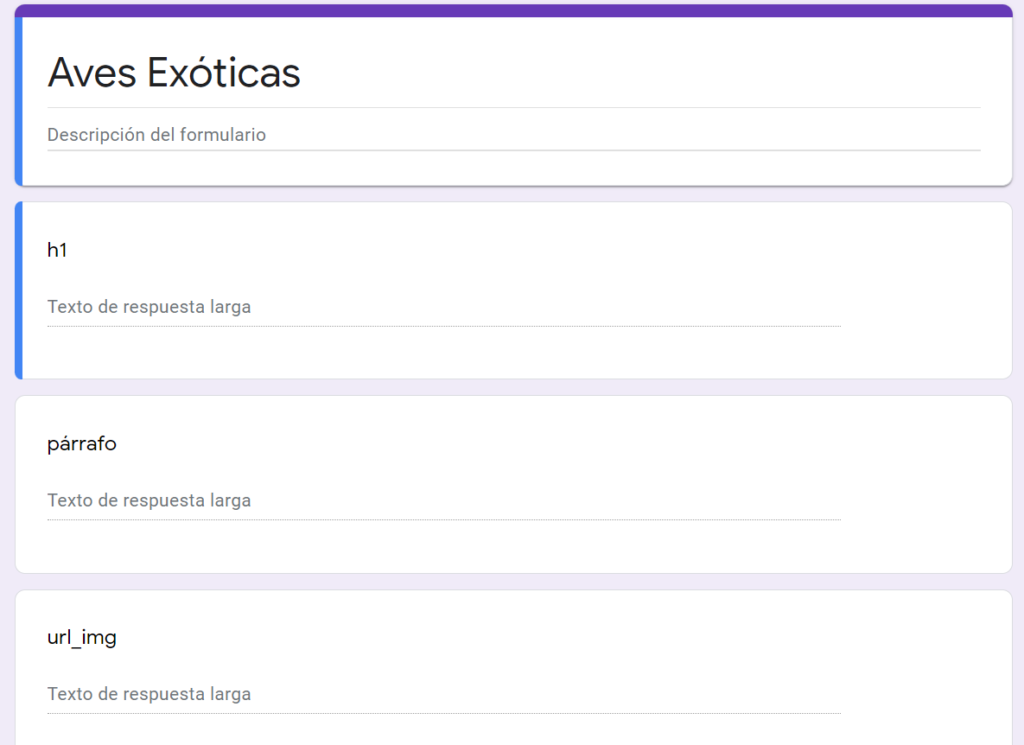
Tenemos que ir a Google Forms, y crear un formulario nuevo, con la misma cantidad de campos como elementos queremos guardar en el, en este caso son tres, el h1, el párrafo del h1 y la imagen.
Importante colocar el tipo de respuesta "Texto de respuesta larga"
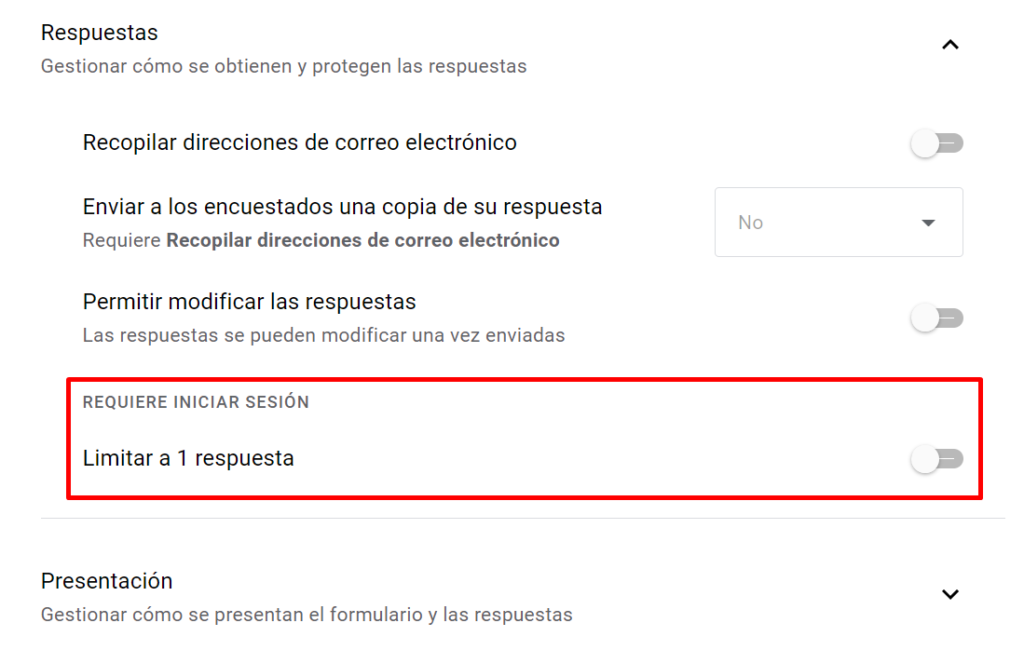
Algo muy importante, el formulario debe ser accesible para cualquier usuario, no solo para usuarios logueados. Esto se configura desde Configuración --> Respuestas 👇
Segundo Paso (Obtenemos URL y Parámetros del FORM)
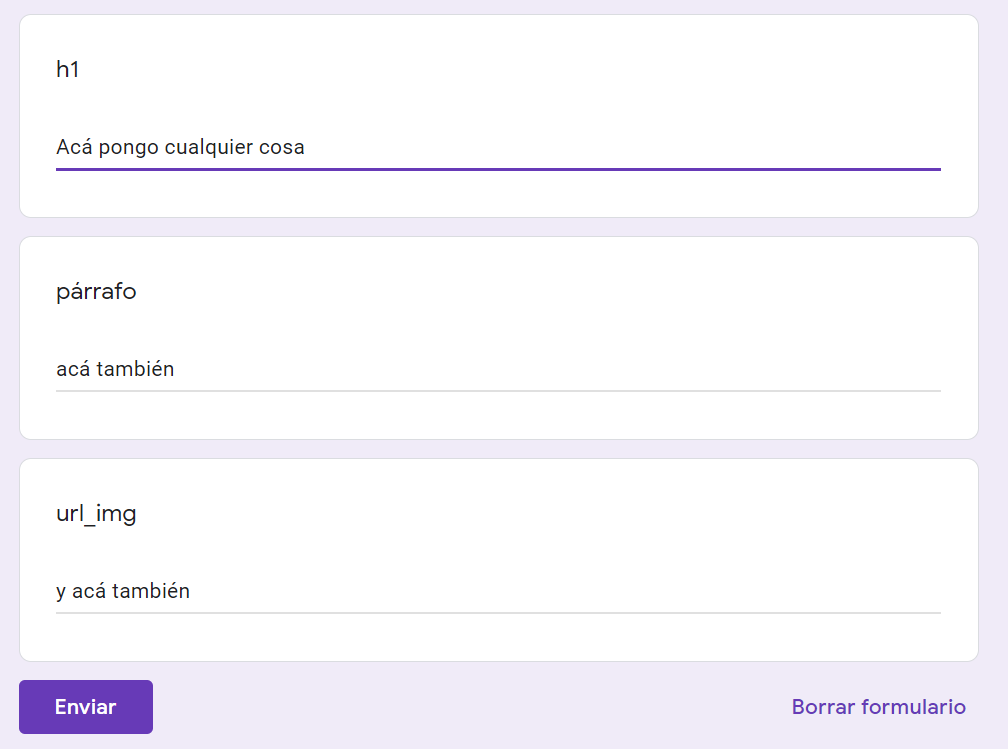
Ahora, vamos a cargar una respuesta en nuestro formulario, pero no sin antes abrir la consola del Chrome (F12), ya vas a ver lo que estamos por hacer 😎
Antes de darle "Enviar" abrimos la consola y nos vamos a la solapa RED, al darle al botón, vamos a ver algo como esto 👇
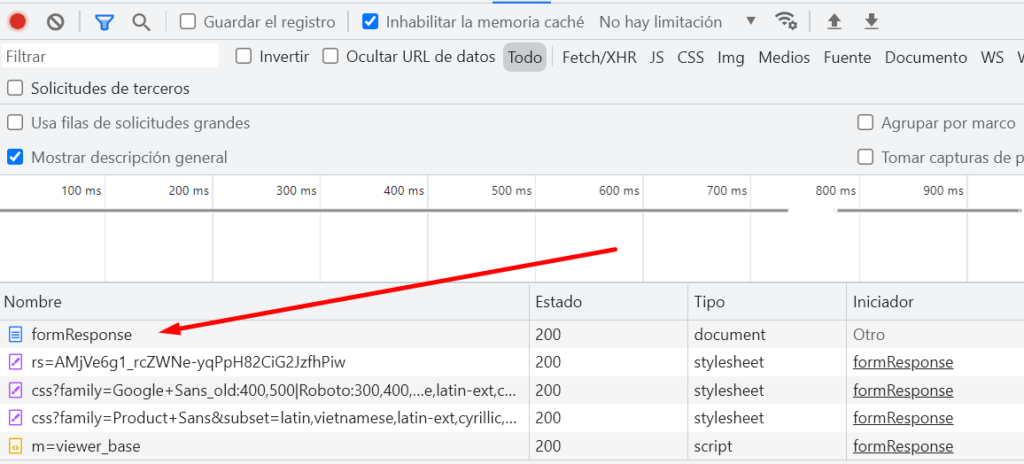
Ahora, hacemos clic en la solicitud formResponse, y vamos a la solapa "encabezado" deberías ver lo siguiente.

Ahora, nos guardamos esa URL y la copiamos en esta linea del código python, a la izquierda del signo de pregunta "?"
URL_LOG = f"https://docs.google.com/forms/d/e/1FAIpQLSd_381rz3qMuh5esMu3nN4USC1x8RqoIJHaaQQQxFfSXdFedA/formResponse?entry.1028304341={h1}&entry.524117291={parrafo}&entry.155032278={img}" Ya te vas dando una idea de lo que estamos por hacer, ahora tenemos que completar la url con lo que esta en la parte derecha del "?", es decir los parámetros del formulario, esas son los nombres de las variables que utiliza nuestro formulario para impactar la info.
Eso lo vemos desde la solapa "carga útil" de la consola
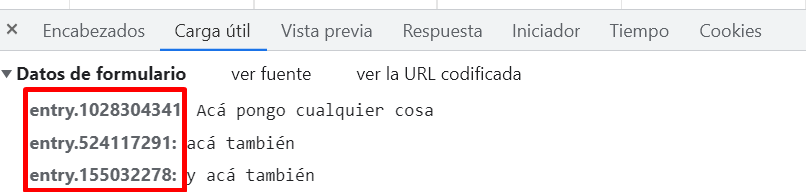
En la misma linea del código Python, colocamos esas variables. en cada una según corresponda. 🙂
Tercer Paso (Cargando los datos)
Esta es la parte mas linda, vamos al Google Sheets asociado a nuestro formulario y vemos como se va llenando poco a poco. 😎
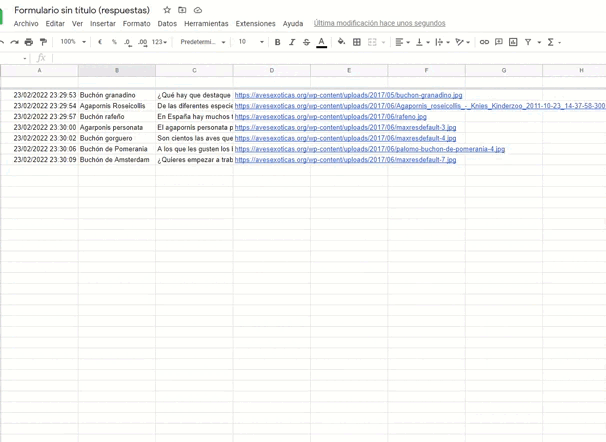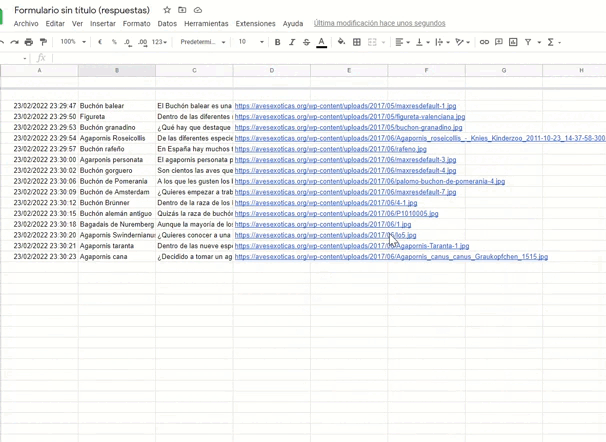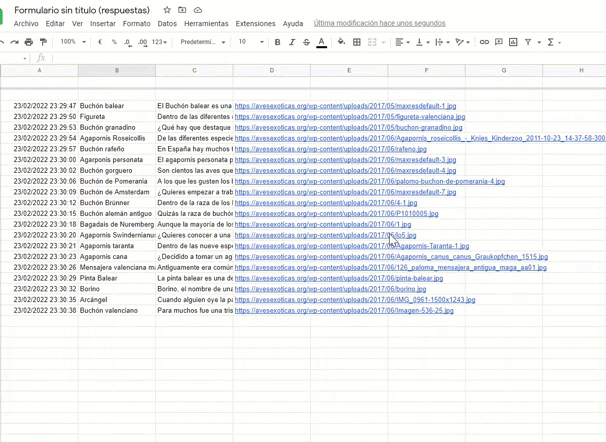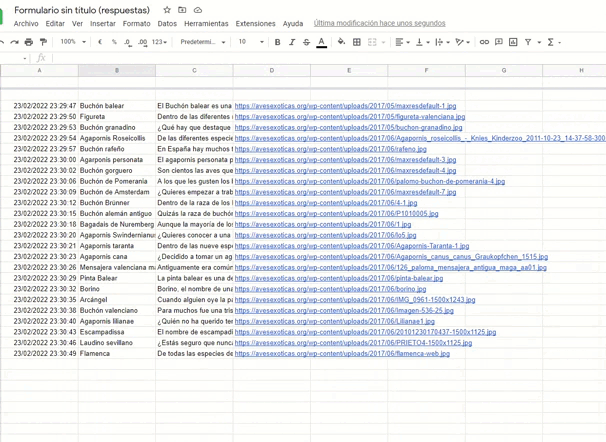
💡 Algunos pensamientos
Como te abras dado cuenta, si bien este articulo lo puede seguir cualquiera si no tenes un perfil técnico se te va a complicar un poco.
Pero no te preocupes por es normal, como fije antes me ofrezco ayudarte a implementarlo y explicar lo que necesites, solo escribirme en los cometarios o por Twitter y te ayudo en lo que pueda.
Así que bueno, ya esta todo dicho, no me enrollo mas, espero que te sirva y pueda incentivarte aprender algo nuevo todos los días. 🙂
Chau Chau!! 👋👋
Deja una respuesta
Mas cositas